How to disable blue (power)LED on PowerDock2? & expled not working properly?
-
Hi guys,
I'm new to omega but I was wondering if someone can help me out with turning off the blue LED (power indicator, I'm guessing) light on the PowerDock2? Or maybe show me in which file the settings are...
Additionally, I tried messing around with the expled command, but it just changed the flickering lights of the battery level indicator. Also it did not change the colors, as explained in those docs. Also, now that the flickering is messed up, can someone give me the default values, so I can revert back to normal again?
All the best,
-
I do not know for sure, but I think that it is impossible to turn off the blue LED, as it turns on when power is applied to PowerDock2.
-
@Vukan-Vuk Yes, @CAP-33 is correct - you can not turn off the POWER LED of Power Dock without some hardware action / modification.
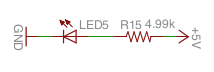
Theexpledtool - originally - is able to control the RGB LED of an Expansion Dock via GPIO15, 16, 17.
See also Expansion Dock > Using the Dock > Controlling the RGB LEDPower Dock 2 has a virtual PB (PushButton) that we can push with the
power-dock2utility via GPIO16 (or unintentionally because GPIO16 is floating by default ;-).
See also Checking the Battery LevelUp to now I thought that PB is effective only if a battery is connected to the board.
It seems you have found a creative way when you are keep pushing it with anexpledcommand - theoretically 200 times per second ;-).You should try to stop the PWM signal on GPIO16 with
fast-gpio set-input 16- this was the default state of GPIO16.
Notes to @Lazar-Demin
Software PWM on the Omega’s GPIOsUsing the Omega’s GPIOs > Fast-GPIO > Generating a PWM signal on a GPIO:
Generate a software-based Pulse Width Modulated (PWM) signal on a selected pin. Specify the desired duty cycle and frequency of the PWM signal.
fast-gpio pwm <gpio> <freq in Hz> <duty cycle percentage>
This will launch a background processthat will generate the PWM signal.
...
To stop the PWM signal, set the GPIO’s value:
fast-gpio <gpio> 0Correctly:
fast-gpio set <gpio> 0- set the output LOW (if there's an active LOW LED then it will be ON) or
fast-gpio set <gpio> 1- set the output HIGH (if there's an active LOW LED then it will be OFF).# Omega2+ v0.2.2 b201 root@Omega-99A5:~# expled 0xf21133 Setting LEDs to: f21133 Duty: 6 94 80 root@Omega-99A5:~# ps | grep fast-gpio 4641 root 1160 S fast-gpio pwm 17 200 6 4644 root 1160 S fast-gpio pwm 16 200 94 4647 root 1160 S fast-gpio pwm 15 200 80 4761 root 1188 S grep fast-gpioAre these
fast-gpio pwm ...processes running in the background really?