What could be causing this error?
-
Been working on the Time-lapse Webcam tutorial in the Onion Handbook. (Onion Team, thanks for the writing the book!). It help to reset our Omega2+ and start from scratch as now the code matches the tutorial's code.
Now receiving the following error(s):

For now, just focusing on the first one - "can't cd to /root/sd/timeplase/" (was previously /root/sd/timelapse).
Here is the code:
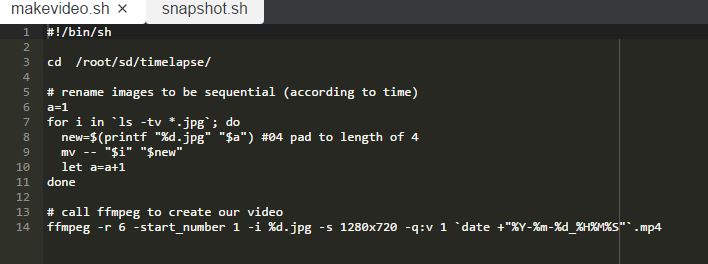
Tried many searches (stackoverflow, etc..) and variations to line 3, but no success. It seems like a simple, but elusive, resolution.
Any ideas! Thanks in advance.
-
If you followed the tutorial then is more likely that your SD is not mounted.
First error indicates that folder /root/sd/timelapse doesn't exists, and second one depends on listing it's contents, so if folder doesn't exists then there is no content, so can't do 'ls' so 'for' exits.
-
Updated the path and eliminated that error. The shortcut link might not be setup correctly.
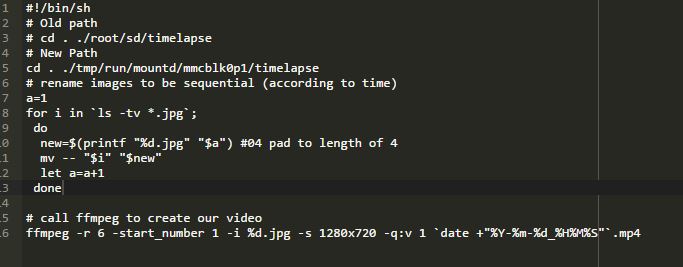
Running ls for /tmp/run/mountd/mmcblk0p1/timelapse does list the *.jpg files.
Now, working on this error.

-
May be shooting in the dark, but put the "do" back on the "for" line (line 8).
-
Revised the code to the following:
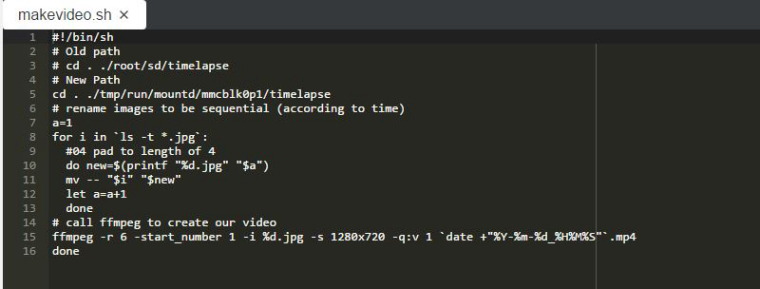
It runs without generating the previous errors, but the results show more trouble shooting is necessary:
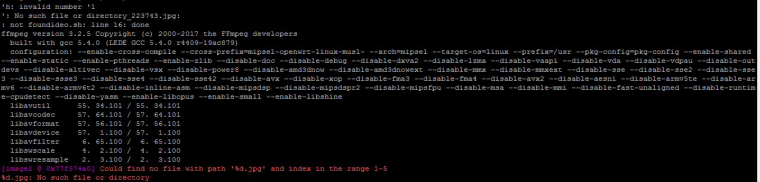
There are *.jpg two files that are now in the directory after the program ran, and the new file(s) should be an *.mp4:
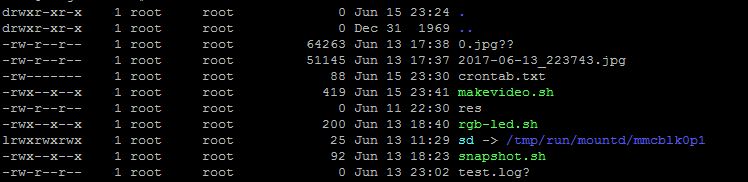
Now, working on to see what is causing it.